이번주에 진행한 미니 프로젝트
조별로 주제 정해서 데이터 튜닝해보기
자료는 Kaggle의 Bank Marketing Data를 사용했다
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib import rc
필수적인 pandas와 numpy를 비롯한 시각화 라이브러리 import
Bank Client Data만 사용하여 해당 고객의 예금 가입 여부를 예측해보았다

1차적으로 pandas profiling으로 자료 파악

Baseline Model을 먼저 만들었다
LogisticRegression, DecisionTreeClassifier, XGBoostClassifier, KNN
이렇게 4개를 활용했다
여기선 내가 맡았던 KNN에 대해서만 작성
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
# 모델 정의
knn_clf = KNeighborsClassifier(n_neighbors=5)
# 학습
knn_clf.fit(X_train, y_train)
필요한 라이브러리 import 해주고
int인 나이만 빼고 나머지는 one-hot encoding 진행
다시 나이와 합쳐주기
#age 제외 encoding 할 데이터
X_encoding = X[['job', 'marital', 'education', 'default', 'housing', 'loan']]
# X에 대한 인코딩 실행
from sklearn.preprocessing import OneHotEncoder
X_encoding = pd.get_dummies(X_encoding)
X_encoding
#encoding 후 합치기
X2 = pd.concat([X['age'],X_encoding], axis=1)
X2.head()
예금 가입 여부는 yes/no이기 때문에 label encoding으로 진행해도 무관할 거라 판단
# y에 대한 인코딩 실행(yes / no 밖에 없어서 라벨인코딩으로)
from sklearn.preprocessing import LabelEncoder
labelencoder = LabelEncoder()
y['y']= labelencoder.fit_transform(y['y'])
전체 데이터 중 33%만 테스트 데이터로 빼두기
#test_size: 0.33
X_train, X_test, y_train, y_test = train_test_split(X2, y, test_size=0.33, random_state=42)
X_train.shape, X_test.shape, y_train.shape, y_test.shape
모델 학습시키기
from sklearn.neighbors import KNeighborsClassifier
# 모델 정의
knn_clf = KNeighborsClassifier(n_neighbors=5)
# 학습
knn_clf.fit(X_train, y_train)
모델을 예측시켜 나온 점수 비교
knn_clf.score는 0.877정도 나왔다
knn_clf.score(X_test, y_test)
y_pred = knn_clf.predict(X_test)
print(classification_report(y_test, y_pred))
이건 y_pred의 결과
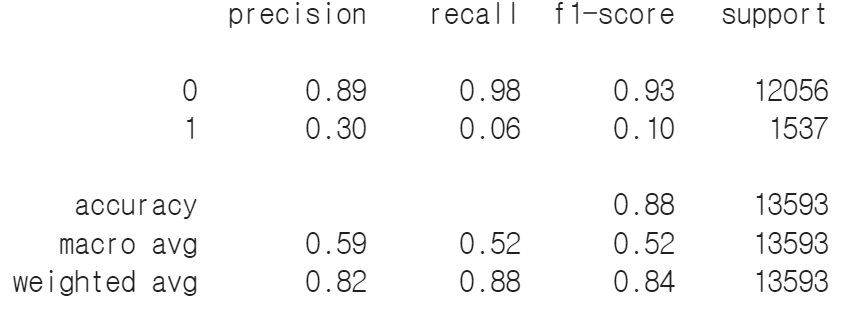
데이터 튜닝을 위한 2차 DEA를 진행했다
나이를 10단위로 잘라 구간 설정
# 나이대를 10 단위로 변경
bank3['age'] = pd.cut(bank3.age, bins=[0,19,29,39,49,59,69,79,89,99], labels=['10s','20s','30s','40s','50s','60s','70s','80s','90s'])
근데 2차 DEA에서 yes와 no의 심한 불균형 발견

진작에 발견하지 못한 건 비슷할 것이라는 편견 때문
no를 5천개만 비복원 추출해서 진행했더니
0.886 -> 0.612 정도로 score가 떨어졌다 (LogisticRegression 기준)
그래서 베이스라인과 같은 데이터 상태로 진행
knn.clf_score가 0.879로 소폭 상승했다
knn_clf.score(X_test, y_test)
y_pred = knn_clf.predict(X_test)
print(classification_report(y_test, y_pred))
y_pred 결과

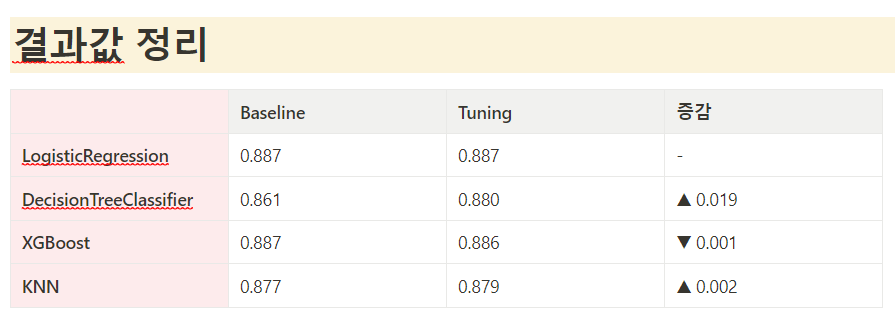
결과적으로 다음과 같다
여기선 KNN만 설명했지만 다른 결과도 같이 게시한다
이 미니 프로젝트를 통해 얻은 것은
1. 모델링 전에 자료를 잘 파악해야한다는 것
2. 데이터 양에 따라 나오는 score가 많이 바뀐다는 것
크게 두가지다
그 중에 더 중요한 건 당연히 데이터를 섬세하게 잘 파악하는 것
비교해보면 다음과 같다
데이터를 중간에 변형하지 않으면 데이터 튜닝 후 score가 상승하는 모습을 보인다
처음 실행한 방법에서 score가 떨어졌다고 한 것은 데이터의 차이 때문
잘못된 비교였기 때문에 떨어졌다고 할 수 없다



발표 후에 데이터의 불균형을 맞추는 것에 대해서도 수업을 들었다
그건 다음에
👋👋
출처 : Kaggle, 우리 조 발표자료
'우리FISA' 카테고리의 다른 글
| 우리FIS 아카데미(우리FISA) 19주차 AI 엔지니어링 텍스트전처리 (0) | 2023.09.02 |
|---|---|
| 우리FIS아카데미(우리FISA) 18주차 AI엔지니어링 프로젝트 로그 남기기 (1) | 2023.08.27 |
| 우리FIS아카데미(우리FISA) 17주차 AI 엔지니어링 ERD 디벨롭 과정 (0) | 2023.08.20 |
| 우리FIS아카데미(우리FISA) 16주차 AI엔지니어링 파이널 프로젝트 데이터 수집 단계 로그남기기 (0) | 2023.08.10 |
| 우리FIS아카데미(우리FISA) 15주차 AI 엔지니어링 프로젝트를 위한 공부 (0) | 2023.08.06 |