8/28
전처리 시작하기도 전에
공유드라이브에 있는 파일을 코랩에 마운트하는데서 고난
이 글을 보고 해결했다
역시 답은 내 드라이브에 경로를 만들어주는 것 밖에 없나보다
https://sundries-in-myidea.tistory.com/96
구글 콜랩에서 구글 드라이브 공유 폴더 사용하기
구글 콜랩을 모두 공유하면서 사용한다면... 개인 프로젝트로 진행하는 것이라면 굳이 콜랩을 선택하는 것은 사실상 컴퓨터 성능의 문제로 선택하는 경우를 제외하면 없을 것 같다. 하지만, 단
sundries-in-myidea.tistory.com
지지난주는 DB구성
지난주는 크롤링
이번주는 크롤링한 텍스트 데이터 전처리를 해야한다
전처리는 1차 세미나 때와 수업 때 elasticsearch에서 했던 걸 제외하면 거의 처음이라 찾아보면서 해야한다
구글링한 결과 이 블로그를 찾아서 참고해서 해보는 중
https://haystar.tistory.com/11
네이버 영화 리뷰 키워드분석 (4) 전처리 시작
탐색 이제 데이터를 수집하는 것은 끝이 났다. 지금부터는 이 데이터를 가공하는 작업이다. 사실 이 데이터 전처리가 제일 중요하지만, 제일 귀찮고 번거롭다. 암튼 또 시작 ㅠㅠ 이번 단계에서
haystar.tistory.com
진행하다보니 "expected string or bytes-like object"라는 오류가 나서 구글링해봤다

찾아보니 str이 아니라 난 에러라서 str()해주니 해결됐다
https://luv-n-interest.tistory.com/517
[Python]TypeError: expected string or bytes-like object(정규표현식 에러)
사실 타입에러는 어디서나 뜨긴 하는데 나는 정규 표현식 사용 과정에서 에러가 났다. 나는 sub과정 중 났는데 re.sub( #!$!@ , ' ' , text) 중에서 text가 str 이 아니라서 발생한 일이다. str(text)로 수행하
luv-n-interest.tistory.com
이제 시작이지만 하나하나 해결할 때마다 아주 뿌듯하다

모든 순간이 디버깅이었다...
이번엔 띄어쓰기를 위해 github을 install하는 과정에서 문제...
이 분이 만드신 PyKoSpacing을 쓰고 싶은데
https://github.com/haven-jeon/PyKoSpacing
GitHub - haven-jeon/PyKoSpacing: Automatic Korean word spacing with Python
Automatic Korean word spacing with Python . Contribute to haven-jeon/PyKoSpacing development by creating an account on GitHub.
github.com
제대로 install이 안되는 문제 발생

구글링해보니 버전의 문제인거 같아서 찾다보니 이 분이 남긴 답변을 발견해서 시도해보려고 했으나
안되었고 그래서 어떡해야하나 못쓰나 싶어서 선생님께 help 요청
선생님이 찾아보시더니 tensorflow 2.4.0 버전은 python 3.6 ~ 3.8에서만 작동한다고 해서
그럼 버전을 낮춰야 하냐고 여쭤봤는데

앞으로 이럴일 많을 거라고 찾는 방법을 알려주셨는데
이렇게 상단에 보면 Issues가 있어서 질문한 걸 볼 수 있다고

Open은 아직 디버깅이 완료되지 않은 질문이고
Closed는 해결된 것이라고 하셔서 난 Closed를 봤다

여기서 내 은인을 만났다
같은 에러를 질문해주신 분과

답변을 달아주신분

해결된 install 문제
당신들이 내 빛입니다...
예시코드까지 잘 돌아가서 한시름 놨다

8/29
자연어처리 코드
근데 이거 말고도 불필요한게 많아서 많이 걸러내야한다
txt 파일로 넣어서 걸러내고 싶은데 코드를 못 찾아서 열심히 구글링 중
https://blog.naver.com/PostView.nhn?blogId=wideeyed&logNo=221347960543
[Python] 문자열 Cleansing(클렌징)
파이썬에서 문자열을 다루다보면 요구사항에 따라 E-mail 주소 또는 URL 또는 HTML을 제거하거나 ...
blog.naver.com
커뮤니티 특성 상 같은 카드를 언급해도 단어가 자유분방해서 직접 보면서 골라내는 게 제일 낫다고 생각
회의 때 공유해봤는데 해보는 게 좋겠다고 해서 내일부터 시작할거다
근데 크롤링할 때까지만 해도 팀에 도움이 되고 있다고 생각했는데
전처리 시작하면서 내 속도가 맘에 들만큼 안나와서 그런가 좀 힘들다
이렇게 이런저런 방법 생각해가면서 결과를 뽑아가도 전체 기여도는 낮아가지고... 별생각이 다드는군
8/30
이런식으로 보면서 하나하나 골라냈다
게시글이랑 답변 csv 가 나뉘어 있어서 어젠 게시글을 봤고
오늘은 답변보면서 대강 골라냈다

아무래도 양이 방대하다보니 앞에서 골라냈는지 아닌지 기억이 잘 안나서
우선 넣고 난 다음에 중복된 걸 걸러내는 방향으로 잡았다
구글링해서 찾은 이 코드로 진행했다
keyword.drop_duplicates(subset=None, keep='first', inplace=False, ignore_index=False)
참고한 블로그는 여기
[Python] 데이터프레임 중복 제거 :: drop_duplicates
데이터프레임에서 중복되는 행을 제거하고 고유한 값만 남기고 싶을 때 Pandas의 drop_duplicates를 활용하면 된다. import pandas as pd # 중복제거 df.drop_duplicates(subset=None, keep='first', inplace=False, ignore_index=F
mizykk.tistory.com
이런식으로 나왔으면 좋겠는데 안풀려서 한참 끙끙거리다 회의에 참석했는데
아무래도 이런 류를 돌려주는 코드가 없어서 직접 딕셔너리에 분류해서 있으면 +1하는 방식으로 가는 것이 나을 거 같다는 얘기를 듣고 그런 방향으로 하기로 했다
조금만 더 할거 같으면 될 거 같았던 느낌은 역시 환상이었나보다
내일까지는 해가기로 해서 빨리 다시 시작해야한다

이러고 있다가 도저히 아닌거 같아서 선생님께 help

역시 선생님 이번에도 답을 주셨다
근데 이 코드 제일 처음에 하다가 그땐 지금만큼의 전처리가 안되어있던 상태라 그런가 안먹혀서 지웠는데
이렇게 다시 돌아오네

이렇게 list를 flatten 시키고 난 다음에 써야 제대로 쓸 수 있다고 하셨다
counts.most_common()로 하면 전체를 다 조회할 수 있다고
아주 유용하다
def flatten(arg):
ret = []
for i in arg:
ret.extend(i) if isinstance(i, list) else ret.append(i)
return ret
test = flatten(content_results)
from collections import Counter # 딕셔너리를 잘 사용하기 위한 패키지
counts = Counter(test)
counts
tags = counts.most_common(100)
이런식으로 내가 원하는대로 나온다
이제 같은 카드를 골라내는 건 내 눈
우선 counter 라이브러리를 쓰면서 시간이 많이 단축돼서 맘이 놓인다

8/31
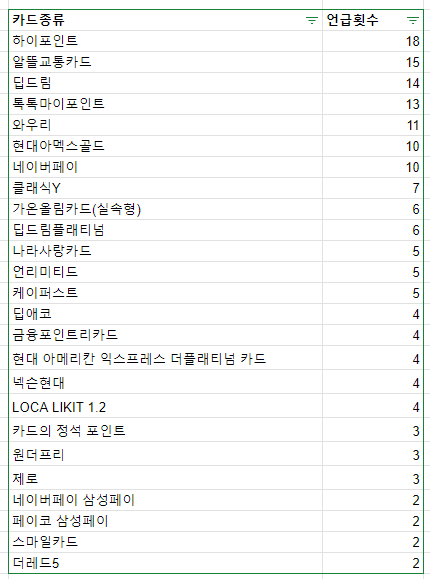
이렇게 카드언급횟수랑 카드사 언급 횟수를 count 해갔다
근데 회의과정에서 카드뿐만 아니라 그 카드가 추천된 맥락이 있어야 추천할 때 더 좋을 거라고 해서 다시 시작 ㅎ
근데 하다보니 내가 contents의 언급횟수만 하고 reply를 안했다는걸 깨달아서 내일 다시 해야함 ㅋㅋㅋㅋ
꼭 이렇게 하나씩 빼먹더라...

9/1
다시 시작
까먹은 csv 파일로 내보내기 부터 시작해서 달리는 중이다
게시글이랑 답변을 따로 처리하다가 이건 아니다 싶어서 리스트를 합치고 한번에 csv파일로 내보냈다

이제 모든건 내 눈에 달렸다....

우선 카드 언급 횟수 count는 끝났고 이제 맥락을 뽑을 차례다
찾아보니 별다른 메서드가 없어서 카드 한 거처럼 눈으로 보면서 해야한다고 생각했는데
리더랑 선생님한테 물어보니 TF-IDF방법이 있다고해서 내일부터 알아보고 실행해볼 예정이다
엘라스틱서치로 하는 방법도 있는데 그건 좀 복잡할 거 같다고해서 그냥 TF-IDF로 해결됐으면 좋겠다
다음주 중으로는 AWS에 올리고 마무리해야하는데 생각보다 빡빡하고
중간에 힘빠지게 하는 소식도 들어서 진도 나가는게 조금 힘드네
출처 : 본문에 있음
'우리FISA' 카테고리의 다른 글
| 우리FIS아카데미(우리FISA) 21주차 AI엔지니어링 RDS, EC2 리뷰 (0) | 2023.09.16 |
|---|---|
| 우리FIS아카데미(우리FISA) 20주차 AI엔지니어링 텍스트 전처리 및 DB (0) | 2023.09.09 |
| 우리FIS아카데미(우리FISA) 18주차 AI엔지니어링 프로젝트 로그 남기기 (1) | 2023.08.27 |
| 우리FIS아카데미(우리FISA) 17주차 AI 엔지니어링 ERD 디벨롭 과정 (0) | 2023.08.20 |
| 우리FIS아카데미(우리FISA) 16주차 AI엔지니어링 파이널 프로젝트 데이터 수집 단계 로그남기기 (0) | 2023.08.10 |