시작하기 전에
requests 라이브러리를 이용해서 HTML 소스를 가져와 처리하는 방법은
- 정적 웹 사이트에서만 가능
- 자바스크립트 코드가 포함된 동적 웹 사이트에서는 적용 불가 → 웹 브라우저에서 보이지 않기 때문
준비
1. 셀레니움 설치
pip install selenium
2. 구글 버전 확인
우측 상단 점 세개 → 도움말 → Chrome 정보
나같은 경우는 들어가니까 자동으로 업데이트가 되고
다시 시작을 해야 적용이 된대서
버튼을 누르니 껐다 켜졌는데 다행히 다른 열려있던 창들이 날아가진 않았다

3. 크롬 드라이버 설치
https://sites.google.com/chromium.org/driver/downloads?authuser=0 ← 이거 누르면 됨
들어가서 다운 받으려는데 뭔가 15버전 이상은 여기로 들어가시오 ~ 하는게 있어서 들어감
들어가니 이런 페이지가 나온다
영어로 나오는데 크롬 번역으로 한글로 바꿔서 봄
내리다보면 여러 버전이 나오는데
나는 안정적인 버전으로 노트북 사양에 맞게 다운로드 했다
다운로드는 나오는 주소를 복사해서 주소창에 넣으면 알아서 다운된다
4. 다운받은 파일 풀고 아나콘다와 같은 경로에 설치파일 옮기기
여기서 좀 애먹었는데 나는 실습하기 훨씬 이전에 아나콘다를 설치해서
경로가 도저히 기억이 안났다
파일에서 검색을 하니 한참을 기다려야해서 친구에게 도움을 청했는데
[Python] 아나콘다의 파이썬 설치 경로 확인하기
파이썬 개발을 진행하면 자주 마주하는 장면이 패키지가 없다는 메세지다. 그럴때면 간단하기 "pip install [설치할 패키지명]" 으로 해결하면 된다. 헌데 하다보니 이상했다. "이전에 설치했는데,
twdatastory.tistory.com
이 블로그를 보내줌
요지는 "Anaconda Prompt"를 실행시키고"where python"을 실행 하는것
그렇게 겨우 찾아서 설치파일을 같은 경로에 복사해서 넣어줬다
시작도 안했는데 벌써 힘빠짐 ㅋㅋ..
데이터 가져오기
1. 스타벅스에서 메뉴 가져오기
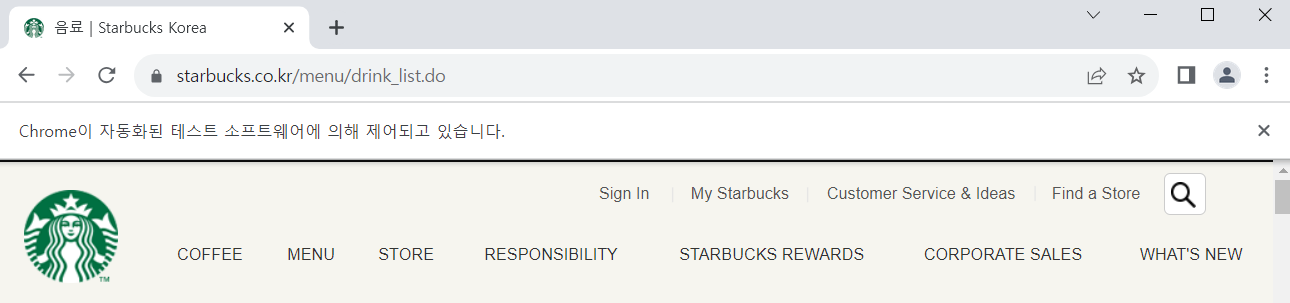
해당 코드를 넣고 난 뒤 실행시키면
접속한 웹 사이트의 제목과 URL이 나온다
from selenium.webdriver import Chrome
from bs4 import BeautifulSoup
driver = Chrome() # 크롬 드라이버 객체 생성
url = "https://www.starbucks.co.kr/menu/drink_list.do"
driver.get(url)
driver.implicitly_wait(3) # 웹 사이트의 내용을 받아오기 까지 기다림
html = driver.page_source # 접속 후 페이지의 HTML을 가져옴
soup = BeautifulSoup(html, 'lxml') # HTML 코드 파싱
print(" -- 접속한 웹 사이트의 제목 :", driver.title)
print(" -- 접속한 웹 사이트의 URL :", driver.current_url)
-- 접속한 웹 사이트의 제목 : 음료 | Starbucks Korea
-- 접속한 웹 사이트의 URL : https://www.starbucks.co.kr/menu/drink_list.do
동시에 아래와 같은 창이 뜬다
신기방기
2. 가져온 HTML 코드 보기 좋게 만들기
HTML에서 메뉴 데이터셋 불러와서
prettify를 이용해 보기 좋게 만들면
drink_products = soup.select('div.product_list dl dd ul li.menuDataSet dl')
print(drink_products[0].prettify()) # 예쁘게 만들기
이렇게 뜬다

3. 메뉴와 이미지 링크 골라내기
그 중에 메뉴 골라내고 이미지 골라내는 코드 넣어주면 결과가 나온다
drink_menu_name = drink_products[0].select_one('dd').get_text()
drink_menu_name
'씨솔트 카라멜 콜드 브루'
drink_menu_photo_link = drink_products[0].select_one('a img')['src']
drink_menu_photo_link
'https://image.istarbucks.co.kr/upload/store/skuimg/2023/06/[9200000004544]_20230629142107817.jpg'
4. 메뉴와 이미지 링크 list로 반환하기
음료 메뉴 전체 이름과 사진링크를 추출하고 리스트로 할당하는 코드이다
append로 리스트에 계속 합쳐준다
제대로 쳐서 넣었는데 오류가 자꾸 나서 멘붕
근데 append 오타때문이었다 ㅎ
오탈자 찾기가 제일 어렵다
찾아준 친구가 화면만 보지말고 글을 읽으라고 했다 ㅋㅋㅋㅋ ㅜ
# 음료 메뉴 전체 이름과 사진 링크 추출, 리스트로 할당
from selenium.webdriver.chrome.options import Options
from selenium.webdriver import Chrome
from bs4 import BeautifulSoup
import pandas as pd
options = Options()
options.headless = True # 헤드리스 모드 할당 -> 크롬을 GUI 없이 수행
driver = Chrome(options=options) # 크롬 드라이버 객체 생성
url = "https://www.starbucks.co.kr/menu/drink_list.do"
driver.get(url)
driver.implicitly_wait(3) # 웹 사이트의 내용을 받아오기 까지 기다림
html = driver.page_source # 접속 후 페이지의 HTML을 가져옴
soup = BeautifulSoup(html, 'lxml') # HTML 코드 파싱
drink_products = soup.select('div.product_list dl dd ul li.menuDataSet dl')
driver.quit() # 웹 브라우저 종료
drink_menu = []
for drink_product in drink_products:
menu_name = drink_product.select_one('dd').get_text()
menu_photo_link = drink_product.select_one('a img')['src']
drink_menu.append((menu_name, menu_photo_link))
drink_menu[0:4]
결과는 이렇게 나옴 !
[('씨솔트 카라멜 콜드 브루',
'https://image.istarbucks.co.kr/upload/store/skuimg/2023/06/[9200000004544]_20230629142107817.jpg'),
('여수 윤슬 헤이즐넛 콜드브루',
'https://image.istarbucks.co.kr/upload/store/skuimg/2023/08/[9200000004750]_20230801101408624.jpg'),
('콜드 브루',
'https://image.istarbucks.co.kr/upload/store/skuimg/2023/07/[9200000004770]_20230720103902092.jpg'),
('나이트로 바닐라 크림',
'https://image.istarbucks.co.kr/upload/store/skuimg/2021/04/[9200000002487]_20210426091745467.jpg')]
전체 메뉴 숫자를 보면 149개라고 나온다
len(drink_menu)
데이터프레임 만들기
1. pandas로 데이터프레임 만들기
pandas import 한 것은 여기서 쓰인다
col_drink_menu = ["메뉴", "사진"]
df = pd.DataFrame(drink_menu, columns=col_drink_menu)
df.head(4)
데이터프레임으로 만들어서 상위 4개만 보여준다
만약 전체를 다보고 싶다면 df만 치면 됨 !
전체 메뉴 갯수가 149개라서 추천은 안함

2. HTML 이미지 태그 만들어주기
아직 끝이 아니다
이미지까지 제대로 나와야 완성 !
이렇게 함수를 만들어주고
# 이미지링크를 HTML img 태그로 만드는 함수
def make_HTML_image_tag(link):
image_width = 80 # 사진 크기
image_tag = f'<img src="{link}" width="{image_width}">' # img 태그
return image_tag
결과를 뽑아내면
make_HTML_image_tag(df["사진"][0])
주소가 나온다
'<img src="https://image.istarbucks.co.kr/upload/store/skuimg/2023/06/[9200000004544]_20230629142107817.jpg" width="80">'
이걸 HTML로 만들면
html_table=df.head(4).to_html(formatters=dict(사진=make_HTML_image_tag), escape=False)
print(html_table)
이렇게 코드가 주르륵 나온다

HTML 파일 만들기
1. HTML import 하고 적용하기
이제 진짜 마지막 !!
IPython에서 HTML을 import해서 적용시켜주면
from IPython.display import HTML
HTML(html_table)
드디어 결과가 이렇게 나온다 !
중간에 append 오타만 아니면 금방했을텐데....

2. 결과물 HTML 파일로 저장하기
HTML 파일로 저장해서
folder = "C:\ITStudy\Final Project\크롤링참고" # 폴더지정
file_name = folder+"starbucks_drinks_menu.html" # 생성할 html 파일명 지정
df.to_html(file_name, formatters=dict(사진=make_HTML_image_tag), escape=False)
print("생성한 파일 : ", file_name)생성한 파일 : C:\ITStudy\Final Project\크롤링참고starbucks_drinks_menu.html
열어보면 짜잔

크롤링에 관심이 있었는데 막상 실습따라해보니 어렵지 않아서
프로젝트에도 잘 써먹을 수 있을 거 같다
화이팅 !
출처 : 『파이썬 웹 스크레이핑 완벽 가이드』, 위키북스
'코딩공부' 카테고리의 다른 글
| [Python] 리스트 정렬하기 (1) | 2023.10.23 |
|---|